
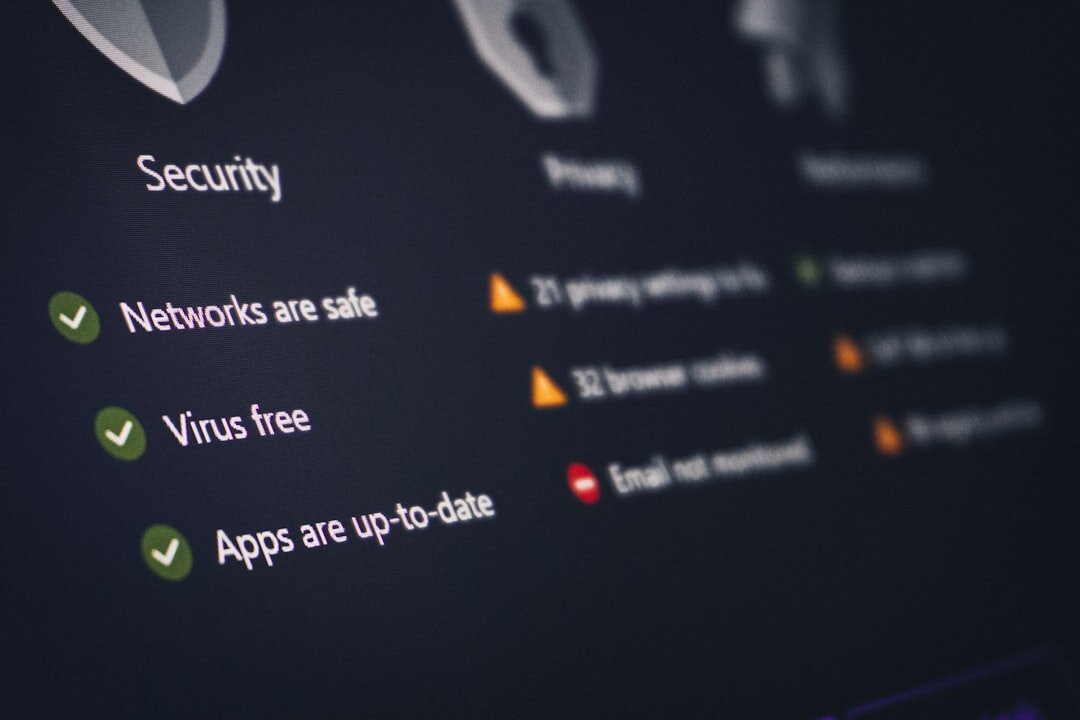
GDPR Article 32 is less about paperwork and more about engineering evidence: encryption, pseudonymisation, access control, backups, logs, and testing. Here is what developers, SaaS teams, and security learners should actually implement. #gdpr #cybersecurity #softwareengineering #dataprotection #cloudsecurity #compliance
When engineers hear GDPR, many immediately think about legal reviews, privacy notices, and dense policy documents. Article 32 deserves a different reaction. It is the part of the regulation that turns privacy into architecture. If your platform stores names, emails, health data, payment details, IP addresses, or employee records, Article 32 asks a practical question: can you prove that your systems protect that data in a way that matches the real-world risk?
That is why auditors rarely stop at paperwork. They want to see the database design, key management setup, session controls, logs, backup tests, and remediation records. For software engineers, security analysts, DevOps teams, and students entering cloud or cyber roles, Article 32 is one of the clearest examples of how compliance becomes infrastructure.
Why GDPR Article 32 matters in day-to-day engineering
Article 32 focuses on the security of processing. In practical terms, organizations must use appropriate technical and organizational measures to keep personal data confidential, accurate, available, and resilient during incidents. The difficult part is that the regulation does not hand every team the same checklist. Appropriate depends on your system design, data volume, user risk, and the consequences of failure.
Even so, the same technical patterns show up across SaaS platforms, student management systems, healthcare tools, HR products, and API-first startups. The strongest teams do not treat compliance as a once-a-year exercise. They build it into schema design, identity management, deployment pipelines, secrets handling, and disaster recovery from the start.
For developers, that shift matters. A polished security policy cannot compensate for a production database with weak permissions. A privacy notice does not help much if sensitive data is readable in plaintext by anyone with database access. Article 32 rewards evidence, not intention, and that is why it feels much closer to platform engineering than to paperwork.
What data is actually covered
The first step is data mapping. Personal data is broader than many early-career engineers expect. It includes names, email addresses, phone numbers, and government identifiers, but it also covers indirect identifiers such as IP addresses, device IDs, location history, support transcripts, and combinations of fields that can point back to a living person.
Teams should classify their data into clear groups such as standard personal data, sensitive personal data, pseudonymised data, and fully anonymised data. This is not just a governance task. Classification affects how systems should be designed. A basic account status field does not require the same safeguards as medical history, financial records, or biometric information.
Auditors often begin with one foundational request: show the data flow. They want to know where personal data enters the system, where it is stored, which services can read it, where it is transmitted, and how it is deleted. If that map is unclear, every later claim about encryption, retention, access control, or recovery becomes harder to defend.
Nine technical controls that make Article 32 real
1. Data mapping and classification
Before changing code, identify every database, queue, object store, analytics sink, and third-party integration that handles personal data. This sounds administrative, but it is deeply technical. Engineers need to know which tables hold direct identifiers, which APIs expose personal records, and which logs accidentally capture user details or tokens.
Good teams maintain a living asset inventory tied to service owners. That lets platform and security teams prioritize the systems that matter most rather than spreading effort evenly across low-risk and high-risk workloads.
2. Pseudonymisation by design
Pseudonymisation is one of the most misunderstood controls in GDPR. It does not mean deleting identity from the business process. It means separating identity from the main working dataset so unauthorized access to one table does not instantly reveal the person behind the record.
In practice, many teams replace direct identifiers in the main application table with a generated UUID or another non-guessable reference. Names, email addresses, and highly identifying values are then moved into a separate lookup table with tighter permissions. Analysts, internal dashboards, and operational services can work against the pseudonymised dataset without routinely touching the re-identification layer.
- Keep direct identifiers out of general-purpose tables whenever possible.
- Restrict the identity lookup table to a small service boundary.
- Use role-based permissions so not every engineer can join both datasets.
3. Encryption at rest with customer-controlled keys
Disk encryption is the baseline, not the finish line. Article 32 conversations often move quickly into key management because auditors want to know who controls the decryption path. Customer-managed keys in platforms such as AWS KMS give organizations better oversight, key rotation, policy control, and auditable access trails than default managed settings alone.
The most important engineering habit here is traceability. Rotation should be enabled. Key usage should appear in centralized logs. Permissions should be narrow enough that developers, administrators, and applications do not all inherit the same level of access. If you cannot show who used a key and when, your encryption story will feel incomplete during an audit.
4. Application-layer encryption for high-risk fields
This is where mature teams separate themselves from merely adequate ones. If a database administrator can run a simple query and read health notes, salary details, passport numbers, or student welfare records in plaintext, storage encryption has not fully solved the business risk.
Application-layer encryption protects specific fields before they ever reach the database. The application retrieves a secret from a vault or secrets manager, encrypts the value, stores ciphertext, and decrypts it only for approved workflows. That means raw database access alone is no longer enough to expose the data. For sectors handling regulated or sensitive records, this extra layer is becoming a practical expectation rather than an advanced nice-to-have.
5. Strong identity and least-privilege access
Access control is not just about employee logins. Service-to-service identity matters just as much. Shared service accounts create blind spots because the audit trail shows only a generic system name instead of the exact workload or operator involved. That makes incident response slower and accountability weaker.
Modern cloud environments solve this with unique workload identities, narrowly scoped IAM roles, and short-lived credentials. In Kubernetes on AWS, for example, IAM Roles for Service Accounts let each service assume a separate identity. Every API call becomes attributable, and privilege boundaries are easier to reason about.
For students exploring real-world security work, hands-on practice in cyber security and ethical hacking internships or cloud computing and DevOps internships often introduces these identity patterns far better than theory alone.
6. Session security and automatic logoff
Long-lived sessions are a quiet compliance problem. If a user leaves a shared device unlocked and the application keeps a valid session alive for hours, personal data is exposed through convenience rather than sophisticated attack techniques. This is exactly the kind of avoidable risk Article 32 expects teams to reduce.
A practical pattern is a short-lived access token, a longer refresh window, secure HTTP-only cookies, and an absolute session timeout. Many teams aim for roughly 15 minutes of inactivity before reauthentication, with an upper session limit of several hours. The exact numbers depend on context, but the principle stays the same: inactive sessions should not linger indefinitely.
7. Audit logging that tells a real story
Cloud provider logs are useful, but they are not enough on their own. Article 32 evidence becomes much stronger when application logs can answer who accessed which personal record, from where, using what role, and for what action. That includes reads, exports, updates, deletions, failed access attempts, and privilege changes.
High-quality audit logs should be immutable, time-synchronized, searchable, and protected from tampering. Just as importantly, they should avoid storing raw secrets or unnecessary personal data themselves. A logging system can quickly become a secondary compliance problem if it turns into an ungoverned archive of sensitive information.
8. Availability, resilience, and tested recovery
Security is not only about preventing access. It is also about restoring access quickly after failure. Single-zone databases, missing backups, and untested recovery plans put organizations at risk even when no attacker is involved. If a database outage makes personal data unavailable for an extended period, that is still a serious operational and compliance issue.
Strong Article 32 programs usually include multi-zone or multi-region resilience where appropriate, automated backups with clear retention rules, defined recovery time objectives, defined recovery point objectives, and scheduled restore tests. The key word is tested. A backup that has never been restored under realistic conditions is a theory, not a control.
- Use redundant infrastructure for critical data stores.
- Test restores on a schedule and record the timings.
- Verify restored data with record counts, checksums, or targeted integrity checks.
9. Continuous testing, vulnerability scanning, and manual pen tests
Article 32 explicitly expects regular testing and evaluation. In modern engineering teams, that means security checks should live inside the delivery pipeline. Container images, infrastructure definitions, dependencies, and cloud configurations should be scanned before release. Findings need owners, remediation deadlines, and closure evidence.
Automated tools are valuable, but they do not catch everything. Business logic flaws, insecure direct object references, token handling mistakes, and privilege escalation paths often require skilled manual testing. Annual penetration tests remain an important control for organizations that process meaningful volumes of personal data or operate customer-facing platforms with sensitive workflows.
The OWASP Top 10, the ICO guidance on security, and ENISA resources are useful references when teams define test scope, evaluate controls, and prioritize remediation work.
The auditor questions engineers should be ready for
Most audits circle back to a small set of recurring questions. The wording varies, but the intent is familiar and highly practical:
- How do you prevent unauthorized re-identification of pseudonymised data?
- Who can decrypt sensitive records, and how is that access logged?
- How do you prove sessions expire and inactive users lose access?
- What are your recovery time and recovery point targets for personal data, and when did you last test them?
- When was the last vulnerability assessment or penetration test, and how were findings remediated?
The right response is not a long speech. It is evidence. Engineers should be prepared to show access-control rules, key rotation status, encrypted field output, session configuration, recovery test records, CI scan results, issue tracker history, and closure dates for critical findings. Mature systems generate that evidence naturally because the controls are embedded in operations, not assembled manually for inspection.
A practical implementation roadmap for SaaS teams
For companies early in the process, Article 32 can feel overwhelming because it touches identity, data architecture, cloud infrastructure, and software delivery all at once. A phased approach makes the work far more manageable.
Phase 1: Establish visibility
- Map personal data across services, databases, analytics tools, and third-party vendors.
- Label systems by data sensitivity and business criticality.
- Identify obvious gaps such as unencrypted storage, shared accounts, over-permissioned roles, or missing backups.
Phase 2: Fix the highest-risk foundations
- Introduce least-privilege access and unique service identities.
- Enable strong encryption and rotate keys automatically.
- Shorten sessions and secure refresh flows.
- Separate identifiers from operational datasets where feasible.
Phase 3: Build evidence into operations
- Centralize application and infrastructure audit logs.
- Schedule restore drills and record the results.
- Add vulnerability scanning to CI and track remediation in Jira or GitHub.
- Commission regular manual penetration testing for critical products.
Students and early-career engineers who want exposure to this kind of work can also explore internship opportunities across security, cloud, data, and development roles. Compliance engineering is no longer a niche specialty. It sits at the intersection of backend design, DevSecOps, governance, and incident readiness.
Why this matters beyond the audit
The most useful way to read Article 32 is not as a legal obstacle but as a design standard for trustworthy software. Pseudonymisation reduces accidental exposure. Field encryption limits insider risk. Unique identities improve accountability. Short sessions reduce unauthorized access. Tested backups protect continuity. Vulnerability management and penetration testing uncover weaknesses before attackers do.
In other words, the controls that satisfy auditors are often the same controls that make products safer, teams calmer, and incident response faster. That is why Article 32 matters so much for modern software engineering. It turns privacy from a promise on a website into something visible in schemas, logs, tokens, roles, and recovery drills.
Teams that embrace that mindset are usually better prepared not just for GDPR scrutiny, but for customer security reviews, enterprise procurement, and the everyday reality of building systems people can trust.
#gdpr #cybersecurity #softwareengineering #dataprotection #cloudsecurity #compliance
 Your IP Address : 216.73.217.78
Your IP Address : 216.73.217.78